
통계를 위한 R언어를 배워보자 Matlab 안녕~
Why R?
R언어는 통계적 계산과 그래픽에 특화되어 있는 오픈소스 언어이다. R은 많은 통계 모델과 데이터를 제공하는데 이를 이용해 통계적 분석을 해보며 사용법을 익혀보자! 이 글에서는 R의 아주 기본적인 내용만 대충 다룰 예정이다.
필자는 에디터로 Rstudio를 사용했다.
R언어 기본
R언어를 시작하기전에 R언어는 내장함수 검색이 아주 편리하다. 함수의 사용법, 매개변수 혹은 함수 사용법이 궁금하다면 다음과같이 검색할 수 있다. 아주 편리한 방법이니 자주 사용하길 바란다.
(1) ?mean
- help(mean)과 같다. 키워드에 대한 설명을 보여주고 특수문자, 기본연산자도 검색이 가능하다. 함수명이 아닌 키워드는는 ""로 감싸 검색해야한다.
(2) ??mean
- help.search("mean")과 같다. 어떤 함수나 명령의 이름을 정확하게 알지 못하고 부분만 알거나 어떤 키워드와 관련된 함수를 찾고자 할때 사용할 수 있다.
(3) example("mean")
- 함수의 예제 코드를 콘솔창에 보여준다.
(4) args(mean.default)
- mean함수의 기본 매개변수를 보여준다.
이제 R에 대해 알아보자!
1. 사칙연산
2+2 # 덧셈
2^3 # 곱셈
1/2 # 나눗셈
2. 할당
할당에서는 '=', '<-', '<<-' 모두 사용가능하다 필자는 '='으로 통일 하겠다. 여기서 의문이 생길것이다. '<-'이런건 왜쓰는거지?
3->x위와같이 화살표방향으로 좌에서 우로도 할당 할 수있다. 하지만 등호는 우에서 좌로만 할당하고 반대로 사용할 경우 오류를 낸다. 추가로 내장함수인 assign을 사용할 수도 있다.
assign('x', 3)
x -> 3
3 <- x
x ->> 3
3 <<- x
x = 3모두 같은 뜻이다.
3. 변수 규칙
- 변수이름에는 '.'(dot), '_'(under score)를 함께 사용할 수 있다.
- 첫 문자로 숫자, '_'(under score)는 피하는 것이 좋다.
- '.'(dot)으로 시작하는 변수명은 특별한 뜻을 가지므로 피하는것이 좋다.
- 대소문자를 구분한다.
- 시스템에서 사용되는 변수는 피해야한다. (예: diff, df, pt, F, T, ...)
- '.'(dot)을 사용할 수 있음을 이용해 객체.속성 으로 변수명을 설정할 수 있다.
데이터 형식
데이터형식은 R언어의 핵심이다. R언어는 벡터데이터 많이 쓰게 되는데 데이터프레임, vector, factor 등 헷갈리는 부분이 많다. 하지만 한번 이해하고나면 정말 쉬워지니 잘 정리해보자.
데이터 형식은 크게 스칼라형과 열거형으로 나뉜다.
- 스칼라형: logical, numeric, integer, complex, character, raw
- 열거형: vector, matrix, array, factor, data frame, list
is.****()함수로 데이터 타입을 확인할 수 있고 as.****()함수로 타입캐스팅이 가능하다.
1. 스칼라형
(1) character
흔히 쓰이는 문자열이다. ""와 ''는 같은 의미를 갖는다. is.character()로 character형인지 확인할 수 있다.
(2) logical
다른언어의 boolean과 같다. TRUE, FALSE 값을 가지며 T, F로도 쓸 수 있다. 주의할 점은 대문자로 써야한다. 마찬가지로 is.logical()함수로 logical형인지 확인할 수 있다.
(3) numeric
기본적인 숫자형 데이터 타입이다. 따로 지정하지 않은 숫자는 numeric형이다. is.numeric()은 이제 그만 말하겠다.
(4) integer
정수형으로 정수 뒤에 L을 붙여준다. integer는 numeric의 부분집합이다.
is.integer(3L) # TRUE
is.numeric(3L) # TRUE
is.integer(3) # FALSE
is.numeric(3) # TRUE
(4) complex
복소수형으로 i를 사용한다.
is.complex(1+2i) # TRUE
(4) raw
raw는 코드를 나타낸다.
rawchar = charToRaw("Hello")
rawchar # [1] 48 65 6c 6c 6f
is.raw(rawchar)
2. 열거형
(1) 벡터(vector)
벡터는 동일타입의 데이터 구조 즉, 일차원 배열(array)다. 벡터 선언, 할당은 다음과 같이 할 수 있다.
age = c(20, 21, 27, 30, 42, 34)c(...)는 concatenation의 약자다.
벡터 연산은 요소연산이 기본이다. 크기가 다른 벡터로 연산을 시도하면 에러가 발생한다.
x = c(2,4,6,8)
y = c(1,2,3,4)
x/y # [1] 2 2 2 2
x+y # [1] 3 6 9 12
3*x # [1] 6 12 18 24간단하게 평균과 표준편차를 구해보면 다음과 같다.
x = c(2,4,6,8)
# 평균
sum(x)/length(x) # [1] 5
# 평균 확인
mean(x) # [1] 5
# 표준편차
sqrt(sum((x - mean(x))^2)/(length(x) - 1)) # [1] 2.581989
# 표준편차 확인
sd(x) # [1] 2.581989
(2) 리스트(list)
객체를 담는 객체다. 파이썬의 list를 생각하면 된다. 같은 형태의 요소가 아니더라도 담을 수 있다.
myList = list(c(1,2,3),3L,"hi",T)
(3) 메트릭스(matrix)
2차원 array와 동일하다. 모든 요소가 동일 데이터타입이다.
matrix(1:12, nrow=3)
(4) 행렬(array)
n차원이 가능하고 모든 요소의 데이터 타입이 같아야한다.
array(1:12, dim=c(3,4))dim은 차원으로 벡터를 넘겨줘야한다. dim=c(3,4)는 2차원 array로 3행 4열로 생각하면 쉽다. 3차원 array를 만들때는 요소가 3개인 벡터를 넘겨주면된다.
(5) 펙터(factor)
범주에 의미있는 이름을 붙일 수 있는 데이터 구조다.
size = c(95,100,105,100,90)
fsize = factor(size)
fsize
# [1] 95 100 105 100 90
# Levels: 90 95 100 105
levels(size) = c("small", "middium", "large", "X-large")
fsize
# [1] middium large X-large large small
# Levels: small middium large X-largelevel은 범주를 뜻한다. levels로 factor의 level에 이름을 붙여주면 factor의 값이 모두 level로 바뀌게된다.
(6) 데이터 프레임(data frame)
SQL의 테이블과 매우 비슷한 형태이다. 행렬과는 달리 각 컬럼은 서로다른 데이터형식도 가능하다.
d.frame = data.frame(name = c("David","Petter","Mary"),
age = c(25, 32, 23),
married = c(F, T, F))
d.frame
# name age married
# 1 David 25 FALSE
# 2 Petter 32 TRUE
# 3 Mary 23 FALSE
그래프
통계와 때놓을 수 없는 것이 데이터 시각화다. R언어를 이용해 데이터 시각화를해보자. 키에 대한 몸무게의 그래프를 그려보자.
weight = c(60, 70, 55, 91, 87, 66)
height = c(1.75, 1.77, 1.64, 1.83, 1.80, 1.73)
plot(height, weight)
#plot(y=weight, x=height)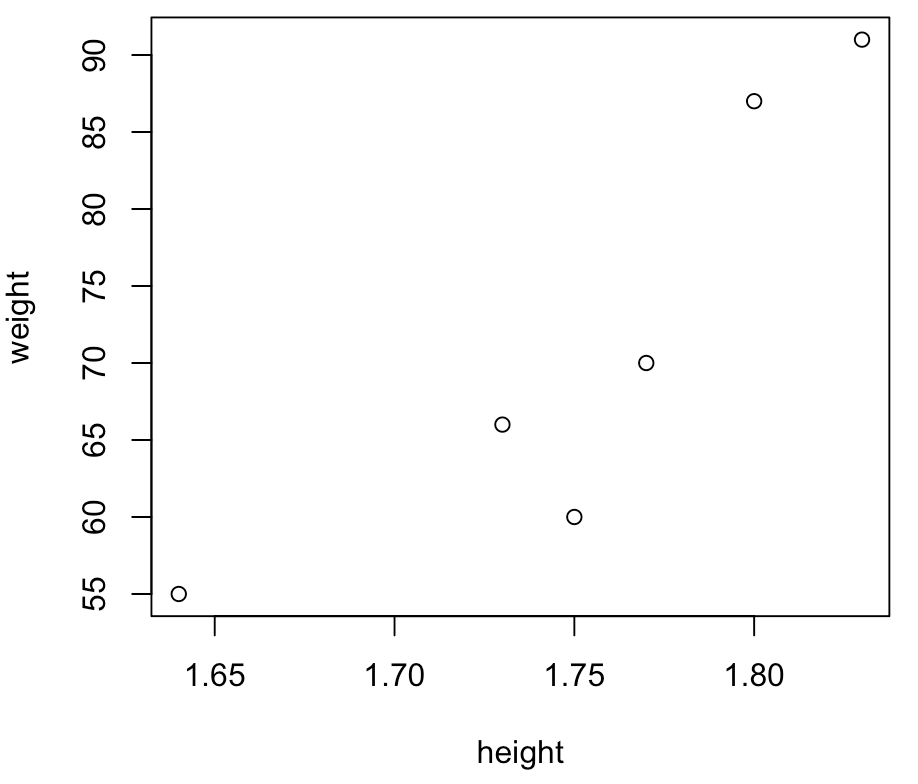
주석도 같은 결과를 나타낸다. R언어에서 함수의 매개변수를 직접 지정할 수 있다. pch(plotting character)변수 값을 이용해 점의 모양을 바꿀 수 있다. pch는 정수값을 갖는다. ?plot 혹은 help(plot)을 이용해 pch변수 값과 다른 변수를 확인 할 수 있다.
직선은 line(x, y)을 이용해 그릴 수 있다. 키에 대한 평균 몸무게를 22.5 * height^2 라고 하고 평균 몸무게를 직선으로 그리면 다음과 같다.
weight = c(60, 70, 55, 91, 87, 66)
height = c(1.75, 1.77, 1.64, 1.83, 1.80, 1.73)
plot(height, weight)
hh = sort(height)
lines(hh, 22.5*hh^2)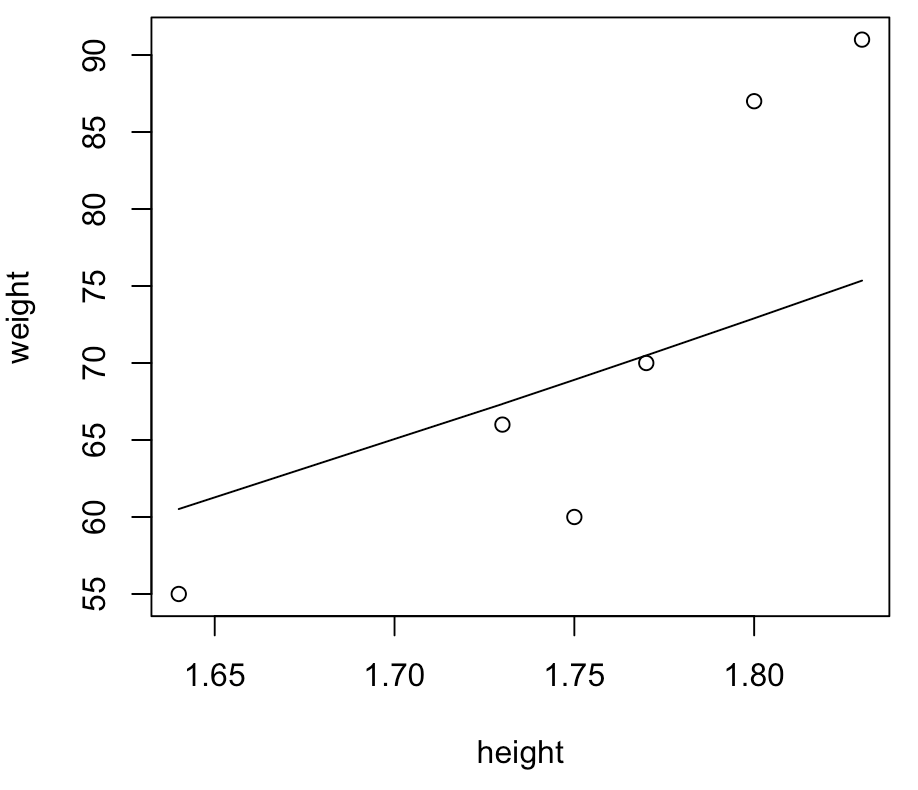
'Languages > R' 카테고리의 다른 글
| [R] 인덱싱(Indexing) (0) | 2021.12.26 |
|---|---|
| [R] R언어의 열거형 데이터 타입 (0) | 2021.11.01 |